Kafka is primarily a distributed, horizontally-scalable, fault-tolerant, commit log. A commit log is basically a data structure that only appends. No modification or deletion is possible, which leads to no read/write locks, and the worst case complexity O(1). There can be multiple Kafka nodes in the blockchain network, with their corresponding Zookeeper ensemble.
If you want to skip directly to the implementation, you can find the repository here.
How Kafka Works
Let's understand how Kafka works in general. You can skip this section to know how Hyperledger Fabric implements this.
Kafka is, in essence, a message handling system, that uses the popular Publish-Subscribe model. Consumers subscribe to a Topic to receive new messages, that are published by the Producer.
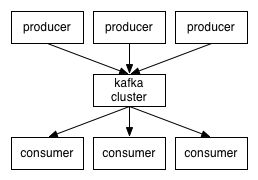
These topics, when they get bigger, are split into partitions, and Kafka guarantees that all messages inside a partition are sequentially ordered.
Kafka does not keep track of what records are read by the consumer and delete them but rather stores them a set amount of time (e.g one day) or until some size threshold is met. Consumers themselves poll Kafka for new messages and say what records they want to read. This allows them to increment/decrement the offset they are at as they wish, thus being able to replay and reprocess events. Consumers are in reality consumer groups, that run one or more consumer processes. Each partition is assigned to a single consumer process so that the same message is not read twice.
Crash Tolerance
The crash-tolerance mechanism comes into play by replication of the partitions among the multiple Kafka brokers. Thus if one broker dies, due to a software or a hardware fault, data is preserved. What follows is, of course, a leader-follower system, wherein the leader owns a partition, and the follower has a replication of the same. When the leader dies, the follower becomes the new leader.
If a consumer is the one subscribing to a topic, then how does he know which partition leader to grab the subscribed messages from?
The answer is the Zookeeper service.
The Zookeeper Service
Zookeeper is a distributed key-value store, most commonly used to store metadata and handle the mechanics of clustering. It allows clients of the service (the Kafka brokers) to subscribe and have changes sent to them once they happen. This is how brokers know when to switch partition leaders. Zookeeper is also extremely fault-tolerant as it ought to be, since Kafka heavily depends on it.
Metadata stored here comprises,
- The consumer group's offset per partition (although modern clients store offsets in a separate Kafka topic)
- ACL (Access Control Lists) — used for limiting access/authorization
- Producer & Consumer Quotas —maximum message/sec boundaries
- Partition Leaders and their health.
You can read more about Zookeeper here.
Kafka in Hyperledger Fabric
To understand the working, it is important to know certain terminologies.
- Chain - The log that a group of clients (a "channel") has access to.
- Channel - A channel is like a topic that authorized peers may subscribe to and become members of the channel. Only members of a channel may transact on that channel, and transactions on a channel are not visible on other channels.
- OSN - It is the Ordering Service Node, or in fabric terms the Orderer node. These are connected to the endorsers and peers, which are our clients. These ordering service nodes
- Do client authentication,
- Allow clients to write to a chain or read from it using a simple interface, and
- Do transaction filtering and validation for configuration transactions that either reconfigure an existing chain or create a new one.
- RPC - Remote Procedure Call is a protocol that one program can use to request a service from a program located in another computer on a network - without having to understand the network's details. In general, a procedure call is also sometimes known as a function call or a subroutine call.
- Broadcast RPC - The transaction submission call, from a node to the orderers.
- Deliver RPC - The Deliver request, what happens after the transaction is processed via the Kafka brokers and is served to the clients on the receiving side.
Note that even though Kafka is the "consensus" in Fabric, stripped down to its core, it is an ordering service for transactions, and has the added benefit of crash tolerance.
What Actually Happens
- For every chain, we have a separate partition.
- Each chain maps to the single partition topic.
- The OSNs after confirming the permissions in the chain relay the incoming client transactions (received via the Broadcast RPC) belonging to a certain chain to the chain's corresponding partition.
- The OSNs can then consume that partition and get back an ordered list of transactions that is common across all ordering service nodes.
- The transactions in a chain are batched, with a timer service. That is, whenever the first transaction for a new batch comes in, a timer is set.
- The block (batch) is cut either when the maximum number of transactions are reached (defined by the batchSize) or when the timer expires (defined by batchTimeout), whichever comes first.
- The timer transaction is just another transaction, generated by the timer described above.
- Each OSN maintains a local log for every chain, and the resulting blocks are stored in a local ledger.
- The transaction blocks are then served to the receiving clients via the Deliver RPC.
- In the case of a crash, the relays can be sent through a different OSN since all the OSNs maintain a local log. This has to be explicitly defined, however.
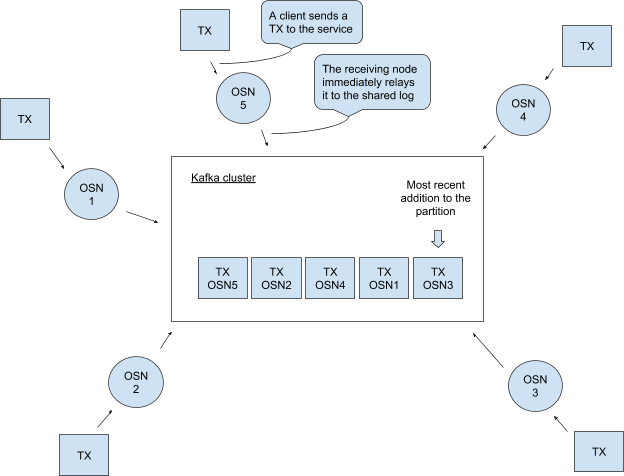
An Example
Consider the figure below. We consider OSNs 0 and 2 to be the nodes connected to the Broadcasting Client, and OSN 1 to be the node connected to the Delivery Client.
- OSN 0 already has transaction
foorelayed to the Kafka Cluster. - At this point, OSN 2 broadcasts
bazto the cluster. - Finally,
baris sent to the cluster by the OSN 0. - The cluster has these three transactions, at three offsets as seen in the diagram.
- The Client sends a Delivery request, and in its local log, the OSN1 has the above three transactions in Block 4.
- Thus it serves the client with the fourth block, and the process is complete.
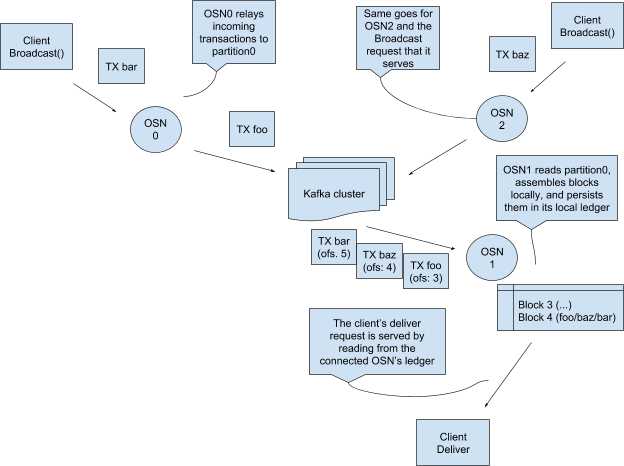
Kafka mechanism in Fabric.
Kafka is probably a great thing to happen to the Hyperledger Fabric, due to its high performance. Multiple orderers use Kafka for being in sync, Kafka isn't an orderer in itself. It just connects two orderers with a stream. Even though it supports crash tolerance, it does not offer protection against malicious nodes in the network. An SBFT based solution can help avoid this problem but is yet to be implemented in the Fabric framework. The issue can be tracked here. All in all, it is suited for production, as compared to the Solo mechanism also implemented in Fabric. As mentioned earlier, you can play with the network by following the steps in the repository hosted here.
If you have any queries or doubts, do let me know by commenting below.


