

Let us see how we can use AI to detect facial landmarks for improved analysis and accuracy.
Object Recognition
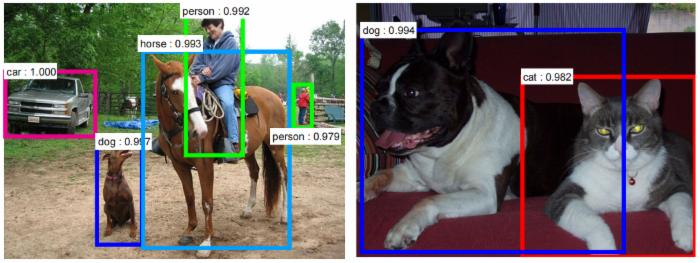
To enable the computer to differentiate between objects was the first instinct in the computer vision study. It was all started with the goal of making computers find the labeled item in an image or the video it captures. With the help of machine learning, we will be able to achieve 95% accuracy in making the computer detect objects and label them in the right way.
When a computer is trained with lots and lots of images of humans, cats, dogs, apples and oranges, it could easily find them in the image.
Beginner’s Note:
There are many image classification frameworks and libraries available for you to start with. Some of the resources for you to checkout online,
- DeepGram is one easy model to system framework.
- Keras is a top-level API-program that uses either Tensorflow or Theano as backend. This is easy for beginners to jump in before considering pure Tensorflow or Theano.
- Tensorflow for Beginners
- Tensorflow solving classification problem
But the real world problem is too complex. All we wanted is to find whether the cat is Fluffy or Slushy. And whether the person is Michael or James.
So after the classification problem was solved, there arises the problem of particularly recognizing in specific classes.
Let’s write our face detection system
For many years, image recognition was a tedious task only because of the complex communications that occurred when a very high number of dimensions overlap to happen at once. 10 years back, the systems couldn’t do all the computations that were very much needed for the system to come up with results and learn again from losses - that was too time-consuming and the complex calculations weren’t supportive. But, now with advancement in technology, our computers can parallelly run different calculations at the same time.
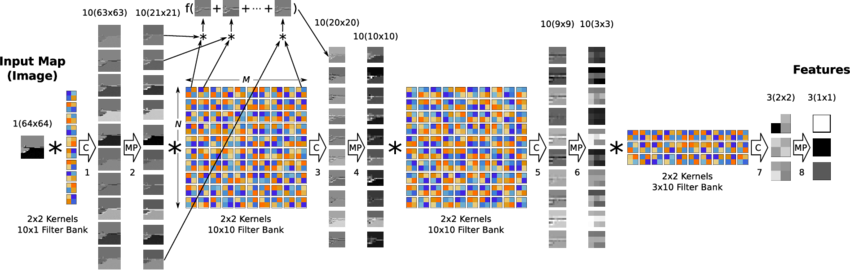
So what did we use to extract the important features from the image of a face? Well, a lot of things! And yes, computers need everything in the numeric notation for it to process. So, what is the easiest way to extract the important features, so that our computer can consume all of it and tell us ‘That’s Michael Jackson. I know him’ ?
We went through lots of algorithms and papers to make that happen. In the few days of hands-on experience, what we can understand is, computers can work on raw image data. We can use CNN (Convolution Neural Net - refer to the image above) to make it extract the important features all by itself. But the point is ‘it’s going to take a lot of time and a lot of faces’. Yeah, we totally learned that by spending a lot of time on this. And we slowly understood that all the faces must have common important points. We can tell the key-points based on which it has to find the difference among the faces - so, we started working on finding the algorithms that help to find key-points in faces.
And with all the research (and by spending a lot of time on google) we found that HOG works better for facial recognition at nearly 35% faster than simple-CNN. OpenCV has libraries that could help to get the HOG of faces and helps us with comparing. And another point is, the HOG images are 1-channeled (no difference in having it 3-channeled), and so the computing matrix is nearly 33% of the original size.
Beginner’s Note:
Can’t understand terminologies like CNN or HOG? Okay. To help you people out, I am going to explain it in our beginner’s terms 😉 😉
So, Neural Network is a mathematical model that works by adapting its important parameters i.e, it will try to reduce the loss. For example, when I am trying to find if an image is an orange or apple, the neural net first thinks that the apple is in ‘orange’ color and mistakes ‘every orange as an apple’. Then it will compare its results with the real ones. And then it tries not to say the things in ‘orange’ color as apple. So its loss is reduced. Slowly it will correct the values of its important parameters.
A CNN is a subset of Neural Net. A (people-say-complex) model that uses convolution algorithm. This eradicates the positioning restrictions that come up with Normal Vanilla Neural Net.
This article might help you with a deeper understanding.
HOG is a feature descriptor. There are many feature descriptors. As its name suggests, it helps to find the ‘important’ feature in a given input. As per wiki, HOG’s technique counts occurrences of gradient orientation in localized portions of an image. Because of this, we can find the important swatches of a feature.
For a detailed implementation on How to use HOG and Where to use HOG, please have a look at this fine article

Now, by training our machine with this smaller image of HOGs, and with appropriate labels, our computers can understand who that is. Now its become a simple image recognition problem.
The Real-time implementation
This is the easiest part of the whole case study. OpenCV reads video and we can just send 1 image (per 20 frames) as an image to the Image Recognition Model we created earlier. We created a python bot that is linked to our office webcam, which switches on every day and when it sees you for the first time greets you ‘Hola’ or ‘Good Morning’ or ‘Guten Morgen’. Cool, isn’t it?


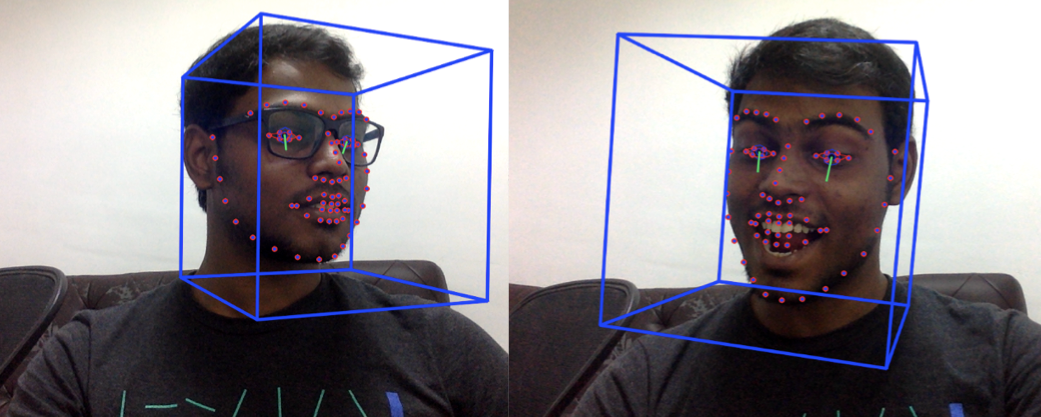

(The image above is a working example that we tested at our HQ)
Subscribe to our newsletter
Get the latest updates from our team delivered directly to your inbox.
Related Posts
AI in 2024: What Actually Worked and What’s Coming Next
AI is everywhere, and it’s not just for the big players. Here are some of the most interesting AI projects that worked in 2024.
Building an AI-powered Knowledge Base
Why we built an internal AI-powered Knowledge Base, and gave it away to our customers.
Skcript's Enterprise AI Manifesto
Our strict guidelines on how we build Enterprise AI products at Skcript.