
The best way to learn is by asking questions. We will proceed that way. There will be many useful links, in case you want to go through them in detail.
What is Insurance?
Insurance is basically an arrangement by which a company or the state undertakes to provide a guarantee of compensation for specified loss, damage, illness, or death in return for payment of a specified premium. The compensation process is initiated by a claim. We will deal with Property & Casualty(P&C) type of Insurance here.
What is the current flow process of an Insurance claim?
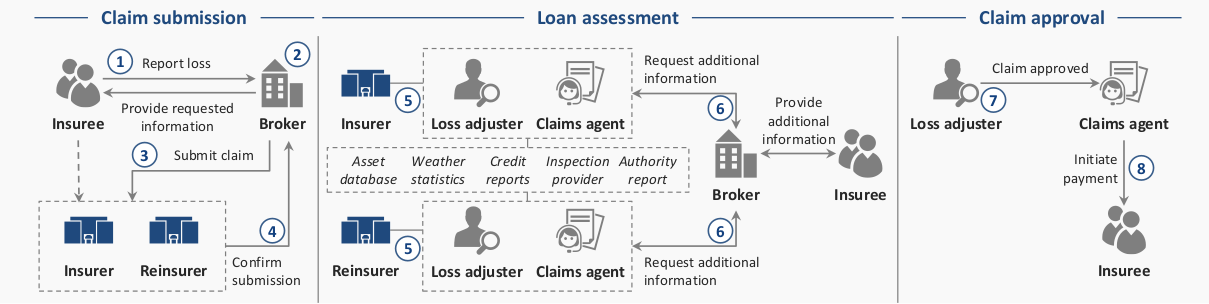
Image Credit : World Economic Forum
An Insuree may report a loss or a claim to a broker, and with the required information submits it to the Insuring authorities, namely the Insurer and if applicable, the Reinsurer . The claim submission is confirmed via a receipt to the Insuree. The Claims Agent may request for additional information for the claim, via an external source. After these steps, if all the conditions are satisfied, the claim is approved, and the payment is initiated via the Insurer’s Claim Agent.
What are the problems with the current situation?
Undesirable customer experience: To initiate a claim, the insuree must complete a complex questionnaire and maintain physical receipts of the costs incurred by the loss
Costly intermediaries: brokers act as intermediaries during processing, adding delays and costs to the submission
Fragmented data sources: Insurers must establish individual relationships with third-party data providers to get manual access to supporting asset, risk and loss data that may not be updated
Fraud prone: The loss assessment is completed on a per-insurer and per-loss basis with no information sharing between insurers, increasing the potential for fraud and manual rework
Manual claim processing: Loss adjusters are required to review claims and to:
- Ensure their completeness
- Request additional
- Information or use
- Supporting data sources
- Validate loss coverage
- Identify the scope of the
- liability
- Calculate the loss amount
Double Booking: Processing multiple claims for the same accident, adding redundancy.
What system do we propose?
We implement a blockchain based solution for the above problems, wherein the smart contract will be established in the network and will be applied for all the transactions applied or processed.
How does the system proposed fix the problems?
- When we talk about the architecture of the system, blockchain, all the properties are inherited. This means issues such as tampering of data, or node failures will not affect all the other nodes, ensuring safety and security.
- The claims processing will consist of either an application interface, or the use of smart assets for submitting claims. A simple implication of this is the elimination of the need of a broker, saving cost.
- The claim processing is automated completely, and hence there is no unnecessary delay, benefiting the users on both ends.
- The Insurer will seamlessly have access to historical claims and asset provenance, enabling better identification of suspicious behaviour, thus reducing fraudulent activities.
- Integrated data sources ensure the validity of data, thus minimising manual review.
- Payment process is even more simplified due to it being integrated.
- According to the smart contract logic, multiple claims cannot be added for the same accident, thus eliminating double booking.
- In the case of a DDoS attack, since the system is regularly updated with the latest block, accessing any of the active nodes means acquiring the latest data, thus effectively blocking DDoS - which is a highly-desirable trait for network security.
What are the steps of the proposed flow process of an Insurance claim?
The steps can be depicted as follows:
- The Insuree submits a claim via an interface, or perhaps using external sources or sensors, making the Claim application automated.
- The Insurance Policies are verified by a smart contract, and the feedback to the user is almost immediate.
- The secondary data sources are integrated into the network, and provide relevant information to the necessary entity
- Depending on the insurance policy, the smart contract can automate the liability calculation, in the case of a Reinsuring Entity.
- The Insuree finally makes a decision, and payment is initiated via a payment portal embedded in the network.
With what do we implement our solution?
We implement the above system using the Hyperledger Fabric’s chaincode interface, using Golang .
How do we acquire the skills to do so?
To get yourself familiarised with developing on the Hyperledger Fabric, refer to these docs and tutorials .
To understand the architecture in detail, refer to this article .
How do we configure our network?
For development’s sake, let us use 1 Orderer, 1 Organisation and 1 Peer belonging to that Organisation.
We name the channel as mychannel, and the chaincode as mycc
Thus our config files should look as follows
docker-compose.yaml
version: '2'networks: basic:services: ca.example.com: image: hyperledger/fabric-ca environment: - FABRIC_CA_HOME=/etc/hyperledger/fabric-ca-server - FABRIC_CA_SERVER_CA_NAME=ca.example.com - FABRIC_CA_SERVER_CA_CERTFILE=/etc/hyperledger/fabric-ca-server-config/ca.org1.example.com-cert.pem - FABRIC_CA_SERVER_CA_KEYFILE=/etc/hyperledger/fabric-ca-server-config/0cfd2f14a0e3506d17612924d32b36a25e887173b52793e1f4945343fd36ac34_sk ports: - "7054:7054" command: sh -c 'fabric-ca-server start -b admin:adminpw -d' volumes: - ./crypto-config/peerOrganizations/org1.example.com/ca/:/etc/hyperledger/fabric-ca-server-config container_name: ca.example.com networks: - basic orderer.example.com: container_name: orderer.example.com image: hyperledger/fabric-orderer environment: - ORDERER_GENERAL_LOGLEVEL=debug - ORDERER_GENERAL_LISTENADDRESS=0.0.0.0 - ORDERER_GENERAL_GENESISMETHOD=file - ORDERER_GENERAL_GENESISFILE=/etc/hyperledger/configtx/genesis.block - ORDERER_GENERAL_LOCALMSPID=OrdererMSP - ORDERER_GENERAL_LOCALMSPDIR=/etc/hyperledger/msp/orderer/msp working_dir: /opt/gopath/src/github.com/hyperledger/fabric/orderer command: orderer ports: - 7050:7050 volumes: - ./config/:/etc/hyperledger/configtx - ./crypto-config/ordererOrganizations/example.com/orderers/orderer.example.com/:/etc/hyperledger/msp/orderer - ./crypto-config/peerOrganizations/org1.example.com/peers/peer0.org1.example.com/:/etc/hyperledger/msp/peerOrg1 networks: - basic peer0.org1.example.com: container_name: peer0.org1.example.com image: hyperledger/fabric-peer environment: - CORE_VM_ENDPOINT=unix:///host/var/run/docker.sock - CORE_PEER_ID=peer0.org1.example.com - CORE_LOGGING_PEER=debug - CORE_CHAINCODE_LOGGING_LEVEL=DEBUG - CORE_PEER_LOCALMSPID=Org1MSP - CORE_PEER_MSPCONFIGPATH=/etc/hyperledger/msp/peer/ - CORE_PEER_ADDRESS=peer0.org1.example.com:7051 - CORE_VM_DOCKER_HOSTCONFIG_NETWORKMODE=${COMPOSE_PROJECT_NAME}_basic - CORE_LEDGER_STATE_STATEDATABASE=CouchDB - CORE_LEDGER_STATE_COUCHDBCONFIG_COUCHDBADDRESS=couchdb:5984 - CORE_LEDGER_STATE_COUCHDBCONFIG_USERNAME= - CORE_LEDGER_STATE_COUCHDBCONFIG_PASSWORD= working_dir: /opt/gopath/src/github.com/hyperledger/fabric command: peer node start ports: - 7051:7051 - 7053:7053 volumes: - /var/run/:/host/var/run/ - ./crypto-config/peerOrganizations/org1.example.com/peers/peer0.org1.example.com/msp:/etc/hyperledger/msp/peer - ./crypto-config/peerOrganizations/org1.example.com/users:/etc/hyperledger/msp/users - ./config:/etc/hyperledger/configtx depends_on: - orderer.example.com - couchdb networks: - basic couchdb: container_name: couchdb image: hyperledger/fabric-couchdb environment: - COUCHDB_USER= - COUCHDB_PASSWORD= ports: - 5984:5984 networks: - basic cli: container_name: cli image: hyperledger/fabric-tools tty: true environment: - GOPATH=/opt/gopath - CORE_VM_ENDPOINT=unix:///host/var/run/docker.sock - CORE_LOGGING_LEVEL=DEBUG - CORE_PEER_ID=cli - CORE_PEER_ADDRESS=peer0.org1.example.com:7051 - CORE_PEER_LOCALMSPID=Org1MSP - CORE_PEER_MSPCONFIGPATH=/opt/gopath/src/github.com/hyperledger/fabric/peer/crypto/peerOrganizations/org1.example.com/users/Admin@org1.example.com/msp - CORE_CHAINCODE_KEEPALIVE=10 working_dir: /opt/gopath/src/github.com/hyperledger/fabric/peer command: /bin/bash volumes: - /var/run/:/host/var/run/ - ./../chaincode/:/opt/gopath/src/github.com/ - ./fabric:/opt/gopath/src/github.com/hyperledger/fabric/ - ./crypto-config:/opt/gopath/src/github.com/hyperledger/fabric/peer/crypto/ networks: - basiccrypto-config.yml
OrdererOrgs: - Name: Orderer Domain: example.com Specs: - Hostname: ordererPeerOrgs: - Name: Org1 Domain: org1.example.com Template: Count: 1 Users: Count: 1configtx.yaml
---Profiles: OneOrgOrdererGenesis: Orderer: <<: *OrdererDefaults Organizations: - *OrdererOrg Consortiums: SampleConsortium: Organizations: - *Org1 OneOrgChannel: Consortium: SampleConsortium Application: <<: *ApplicationDefaults Organizations: - *Org1Organizations: - &OrdererOrg Name: OrdererOrg ID: OrdererMSP MSPDir: crypto-config/ordererOrganizations/example.com/msp
- &Org1 Name: Org1MSP ID: Org1MSP MSPDir: crypto-config/peerOrganizations/org1.example.com/msp AnchorPeers: - Host: peer0.org1.example.com Port: 7051Orderer: &OrdererDefaults OrdererType: solo Addresses: - orderer.example.com:7050 BatchTimeout: 2s BatchSize: MaxMessageCount: 10 AbsoluteMaxBytes: 99 MB PreferredMaxBytes: 512 KB Kafka: Brokers: - 127.0.0.1:9092 Organizations:Application: &ApplicationDefaults Organizations:How do we start writing the chaincode?
Modularity is key. Hence the directory structure :
- insurance--- claim----- claim.go--- organisation---- organisation.go--- user----- user.go--- errorhandler----- errorhandler.go--- utils----- utils.go--- payments----- payments.go-- main.goclaim.gohandles all claim related operationsorganisation.gohandles all organisation related operationsuser.gohandles all user related operationsutils.gocontains utility functionserrorhandler.gocentralises error handlingpayments.gohandles all payment related actionsmain.gois our main handler that contains the required API methods for Invoking or Querying
Users belong to organisations, and organisations comprise different roles.
How do we write the necessary functions?
There are three necessary parts for writing chaincode -
- Init - is called during chaincode instantiation to initialise any data.
- Invoke - is used to commit transactions to the ledger, can be compared to the POST method.
- Query - is used to query the ledger and mock an invoke function, and doesn’t write the transaction to the ledger. Can be compared to the GET method.
You can understand what they do in greater detail here
So main.go should look like this
package main
import ( "fmt"
"github.com/hyperledger/fabric/core/chaincode/shim" sc "github.com/hyperledger/fabric/protos/peer" "github.com/insurance/claim" eh "github.com/insurance/errorhandler" txn "github.com/insurance/transaction" "github.com/insurance/user" "github.com/insurance/utils")
type SmartContract struct {}
func (s *SmartContract) Init(APIstub shim.ChaincodeStubInterface) sc.Response { return shim.Success(nil)}
func (s *SmartContract) Invoke(APIstub shim.ChaincodeStubInterface) sc.Response {
function, args := APIstub.GetFunctionAndParameters()
txnID := APIstub.GetTxID()
if function == "addUser" { return s.addUser(APIstub, args, txnID) } else if function === "anyOtherFunction" { return s.anyOtherFunction(APIstub, args, txnID) } // as you create the chaincode for adding the rest of the functions, you have to add more conditions in the above snippet
return shim.Error("Invalid Smart Contract function name.")}
func (s *SmartContract) addUser(APIstub shim.ChaincodeStubInterface, args []string, txnID string) sc.Response { // error handling argCheck := eh.ArgumentError(5, args) if argCheck[0] == "Error" { return shim.Error(argCheck[1]) }
userCheck := eh.ExistError(APIstub, args[0]) if userCheck[0] == "Error" { return shim.Error(userCheck[1]) }
// we define a method in the user package that adds a user return user.Add(APIstub, args, txnID)
}
func (s *SmartContract) anyOtherFunction(APIstub shim.ChaincodeStubInterface, args []string, txnId string) { // function body}We define a simple model for our user.
This is how user.go looks like
package user
import ( "encoding/json" "strconv" "time"
"github.com/hyperledger/fabric/core/chaincode/shim" sc "github.com/hyperledger/fabric/protos/peer" "github.com/insurance/utils")
type User struct { ID string `json: "id"` Name string `json: "name"` Role string `json: "role"` OrganizationID string `json: "organizationId"`}
type IdentityRecord struct { ID string `json: "id"` EnrollmentID string `json: "enrollmentId"` UserID string `json: "userId"` Status string `json: "status"` CreatedAt string `json: "createdAt"` RevokedAt string `json: "revokedAt"`}
// args : [ id, name, role, identityRecordId, EnrollmentId ]func Add(APIstub shim.ChaincodeStubInterface, args []string, txnId string) sc.Response { user := User{ID: args[0], Name: args[1], Role: args[2], OrganizationId: args[3]} userAsBytes, _ := json.Marshal(user)
idRecord := IdentityRecord{args[3], args[4], args[0], "Allow", isotimestamp, []string{""}} idRecordAsBytes, _ := json.Marshal(idRecord)
APIstub.PutState(args[0], userAsBytes) APIstub.PutState(args[3], idRecordAsBytes)
return shim.Success(userAsBytes)}As you can observe from the above snippets, we can define methods for doing a myriad of stuff with our respective entities and claim handling. We implement policies according to the use case and embed them in our smart contract. For example, if you were to change the status of a claim, there has to be an authentication middleware endpoint that only lets users belonging to an endpoint.
What do GetState and PutState mean?
They are functions defined in the shim.ChaincodeStubInterface package, that let you get the data from the database and let you commit data to the database respectively.
What database is used to store the ledger transactions?
Hyperledger Fabric uses CouchDB , a key-value type database. Note that state is synonymous to database.
How do we start the network?
We write bash files that can execute all our commands with ease.
- Initiating and Generating Crypto material from
docker-compose.yaml
init.sh
set -evrm -rf ~/.hfc-key-store/*mkdir -p ~/.hfc-key-storecp creds/* ~/.hfc-key-storegenerate.sh
export PATH=$GOPATH/src/github.com/hyperledger/fabric/build/bin:${PWD}/../bin:${PWD}:$PATHexport FABRIC_CFG_PATH=${PWD}CHANNEL_NAME=mychannel
rm -fr config/*rm -fr crypto-config/*
cryptogen generate --config=./crypto-config.yamlif [ "$?" -ne 0 ]; then echo "Failed to generate crypto material..." exit 1fi
configtxgen -profile OneOrgOrdererGenesis -outputBlock ./config/genesis.blockif [ "$?" -ne 0 ]; then echo "Failed to generate orderer genesis block..." exit 1fi
configtxgen -profile OneOrgChannel -outputCreateChannelTx ./config/channel.tx -channelID $CHANNEL_NAMEif [ "$?" -ne 0 ]; then echo "Failed to generate channel configuration transaction..." exit 1fi
configtxgen -profile OneOrgChannel -outputAnchorPeersUpdate ./config/Org1MSPanchors.tx -channelID $CHANNEL_NAME -asOrg Org1MSPif [ "$?" -ne 0 ]; then echo "Failed to generate anchor peer update for Org1MSP..." exit 1fi- Starting the network
start.sh
set -ev
export MSYS_NO_PATHCONV=1
docker-compose -f docker-compose.yml down
docker-compose -f docker-compose.yml up -d
# wait for Hyperledger Fabric to start# incase of errors when running later commands, issue export FABRIC_START_TIMEOUT=<larger number>export FABRIC_START_TIMEOUT=10#echo ${FABRIC_START_TIMEOUT}sleep ${FABRIC_START_TIMEOUT}
# Create the channeldocker exec -e "CORE_PEER_LOCALMSPID=Org1MSP" -e "CORE_PEER_MSPCONFIGPATH=/etc/hyperledger/msp/users/[email protected]/msp" peer0.org1.example.com peer channel create -o orderer.example.com:7050 -c mychannel -f /etc/hyperledger/configtx/channel.tx# Join peer0.org1.example.com to the channel.docker exec -e "CORE_PEER_LOCALMSPID=Org1MSP" -e "CORE_PEER_MSPCONFIGPATH=/etc/hyperledger/msp/users/[email protected]/msp" peer0.org1.example.com peer channel join -b mychannel.blockHow do we install and instantiate the chaincode on the network?
We use another bash script.
install.sh
docker exec -it cli peer chaincode install -n mycc -p github.com/insurance -v v1docker exec -it cli peer chaincode instantiate -o orderer.example.com:7050 -C mychannel -n mycc github.com/insurance -v v1 -c '{"Args": ["getUserDetails", "insuree1"]}'How do we Invoke or Query a function in the chaincode?
We can test the scenario by using our cli container mentioned in docker-compose.yml. By issuing specific query or invoke commands, we can test the features we implement.
Example Usage:
args='{"Args": ["function-name", "args","start","from","here"]'docker exec -it cli peer chaincode invoke -C "$channelname" -n "$chaincodename" -c "$args"# ordocker exec -it cli peer chaincode query -C "$channelname" -n "$chaincodename" -c "$args"We have to specify our function name as the first element in the array, and the rest of the arguments follow.
Going by the above mentioned addUser example,
args='{"Args" : ["addUser", "ent1", "Priyansh", "Insuree", "id1", "enr1", "org1"]}'docker exec -it cli peer chaincode invoke -C "$channelname" -n "$chaincodename" -c "$args"How do we verify the changes in state?
After you commit transactions, if you’re running the network in you local server, as is mentioned in our docker-compose.yaml file above, the CouchDB UI interface will be present at the address
http://localhost:5984/_utils. You can view all the changes to state here.
How do we scale the network?
We simply have to change the configuration files as mentioned above, to accommodate the different types of entities and organisations we will be dealing with. The application endpoint should interact with the network successfully.
What did we learn?
Literally the title itself. A lot more, if you’ve visited the links specified.
Do we want to learn more?
Let me know in the comments.
Subscribe to our newsletter
Get the latest updates from our team delivered directly to your inbox.
Related Posts
10 Gems in Ruby that you will love
Let's go back to basics with Ruby on Rails and see some of the Gems that we use everyday at skcript. #StartWithSkcript
#100DaysOfCommits
Our CTO, Swaathi, talks about our commitment to the #100DaysOfCommit challenge. Join us.
18 Python packages you should be using right now
Let us look at some python packages that will get you started on your machine learning path #StartWithSkcript