We built a tool using natural language processing techniques that can help classify emotions involved in a text. NLP based products can be especially beneficial to businesses that depend on a customer review system. It is also crucial for building products that have a natural language user interface like personal assistants. With the power of machine learning, many interesting applications can now be built with ease. In this article, we introduce our tool, EmoDet and share our experience in building the project. We share the results of our experiments and things we learned from it.
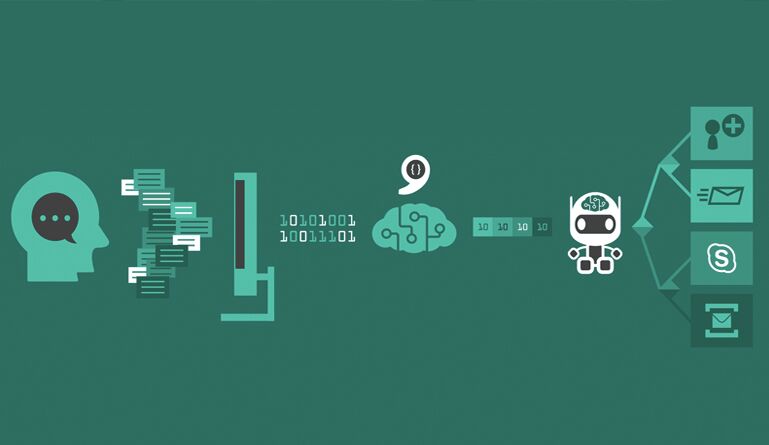
Emodet is an NLP classifier that reads a text and tries to predict the emotions of the text's author. Understanding a users emotion can be very important for a product in many ways.
- It offers a metric to compare with business competitors
- It can help better understand customer satisfaction to enhance customer experience
- It can help develop appealing branding techniques and marketing strategies
- It can help chatbots provide better responses to certain messages
Challenges
We used a twitter dataset to train our machine learning model. We found that the twitter data was not very ideal for the emotion classification task because of the presence of too much variation within the data and the skewness in the frequency of tweets with a particular label. So we collected more data for labels that had less data frequency to balance the data. They were also several noises in the dataset that made the dataset particularly hard to work on.
We set up a preprocessing pipeline to clean all the texts from unrelated symbols, URLs, hashtags, mentions and other irrelevant data.
Once the data was all cleaned up, we were ready for the model selection phase. Our initial idea was to use recurrent numeral networks as they are known to perform better on sequence data. We started with a CNN-biGRU network and started tuning.
model:Sequential()
model.add(Embedding(MAX_VOCAB, 32, input_length=MAX_LEN))
model.add(Conv1D(filters=32, kernel_size=3, padding='same', activation='relu'))
model.add(MaxPooling1D(pool_size=2))
model.add(BatchNormalization())
model.add(Bidirectional(GRU(units=64, dropout=0.2, recurrent_dropout=0.2)))
model.add(Dense(5))To our surprise, the neural network performed very poorly even after training for several epochs and hyperparameters tuning. We believed that the GloVe embedding layer, which is not familiar with the internet slang could be the reason. So we made our model learn its own embeddings. The accuracy gained was still insignificant to qualify for a good model.

The Final Solution
We realized that RNNs don't really perform well on this task with the resources we had after looking at people's work on the internet. This greatly helped us understand the limitations of deep learning in certain situations.
We decided to use shallow machine learning algorithms. After some experimenting and cross validation we chose a logistic regression model that gave the best accuracy which was around 60%.

We also made sure that we used stochastic gradient descent in the model so that the model can be trained further when required without losing anything that the model initially learned. We wrote a python web server using the tornado framework which not only allowed users to make predictions but allowed admins to control the model itself by training/retraining and controlling the model checkpoints. The server allowed training/retraining from different sources.
Model Performance
Still unsatisfied with the accuracy we started exploring the misclassified data and realized that for the most part, the model's predictions described the emotion involved in the text better than the labels themselves and that when the factor of multiple emotions in one text was considered, the model gave really good performance.
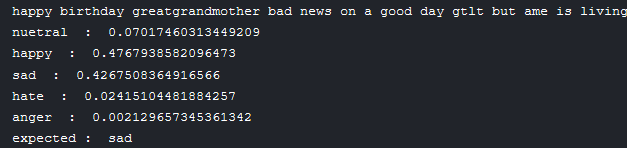
We are so excited to integrate the model into a real life application and see how it performs.
Plans For Improvement
Although our model's performance was satisfactory, there is space for improvement. There are several techniques and methodologies that we didn't try out due to some technical and time limitations. Many techniques which involve using POS based features should also be tested in the future. There were also several deep learning based approaches to the same problem. Exploring more options can help us perform better feature engineering and model selection by bringing the best parts of each technique.

