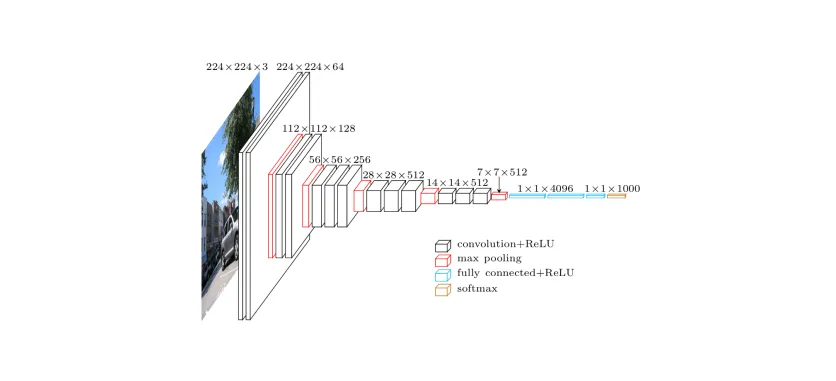
The task of image classification has persisted from the beginning of computer vision. There have been multiple breakthroughs over the years. Before the onset of Deep Learning, computer vision was heavily dependent on hardcoded mathematical formulas that worked on very specific use cases. With the advances in neural networks, convolutional neural networks (CNN) have become very efficient at image classification. Datasets like the Imagenet helped a lot in aiding the CNN learn features faster.
Transfer learning is a method to use models with pre-trained weights on large datasets like Imagenet. This is a very efficient method to do image classification because, we can use transfer learning to create a model that suits our use case. One important task that an image classification model needs to be good at is - they should classify images belonging to the same class and also differentiate between images that are different. Here we can leverage on the pre-trained model’s weights. These models have thousands of classes and can differentiate very well among all classes.
Depending on our dataset, we can use multiple methods in transfer learning. If our dataset is small and similar to the original dataset, we could use the pre-trained convnets as a fixed feature extractor. In this method, we remove the last fully connected layers. A fixed length vector is computed for every image and then a linear classifier is trained for the new dataset. Another method is to actually fine-tune the convnet by retraining the weights by continuing the back-propagation. In this tutorial, we will see the first method of removing the last layer and attaching our own classifier.
Let us consider a case where we have a dataset of flowers that we would like to classify as their respective types. You can download the dataset from here (This can be done programmatically as well). This dataset has 5 classes of flowers - Daisy, Dandelions, Sunflowers, Roses and Tulips. First and foremost we need convert the data into a format that is needed by the Keras function.
Preparing the data Our dataset has the images in their respective class folders. We need to split them into train, test and validation datasets.
data_dir:'flower_photos/'directory:'./'contents:os.listdir(data_dir)classes:[each for each in contents if os.path.isdir(data_dir + each)]
file_paths:[]labels:[]for each in classes: class_path:data_dir + each files:os.listdir(class_path)
for i, file in enumerate(files): path:os.path.join(directory+class_path, file) target:os.path.join(directory, class_path +'/'+each+'_'+ str(i)+'.jpg') os.rename(path, target)
files:os.listdir(class_path) for file in files: file_paths.append(os.path.join(directory, class_path +'/'+file)) labels.append(each)First, we get the class names from the flowers classes in the directory. Then we proceed to rename all the files with their class name appended with respective indices. Then we append them to the file_paths list along with the labels of each image.
Now, we need to split our dataset into train, test and validation. In each of the aforementioned folders, they need to have all the classes as folders. Then we proceed to copy the data from /flowers_photos folder into /data/train, /data/test and /data/validation.
ss:StratifiedShuffleSplit(n_splits=1, test_size=0.2)train_idx, val_idx:next(ss.split(file_paths, labels))half_val_len:int(len(val_idx/2))val_idx, test_idx:val_idx[:half_val_len], val_idx[half_val_len:]
print('Train',len(train_idx))print('Test',len(test_idx))print('Validation',len(val_idx))train_y:[]for i in train_idx: shutil.copy(file_paths[i],'./data/train/'+labels[i]) train_y.append(labels[i])
val_y:[]for j in val_idx: shutil.copy(file_paths[j],'./data/validation/'+labels[j]) val_y.append(labels[j])
test_y:[]print('test_idx',test_idx)for k in test_idx: shutil.copy(file_paths[k],'./data/test/'+labels[k]) test_y.append(labels_vectors[k])
pickle.dump([train_y, val_y, test_y], open('preprocess.p','wb'))print('Data converted into train, test and validation')For the model to train, we have to one-hot encode the data. To achieve this, we use the LabelBinarizer from sklearn. After this, Stratified Shuffle Split from sklearn library to shuffle our data so that all similar data is not clustered together. Then we use the shutil inbuilt library to copy the files into respective folders. After this, the labels for train, test and validation are saved as a pickle for using them during training.
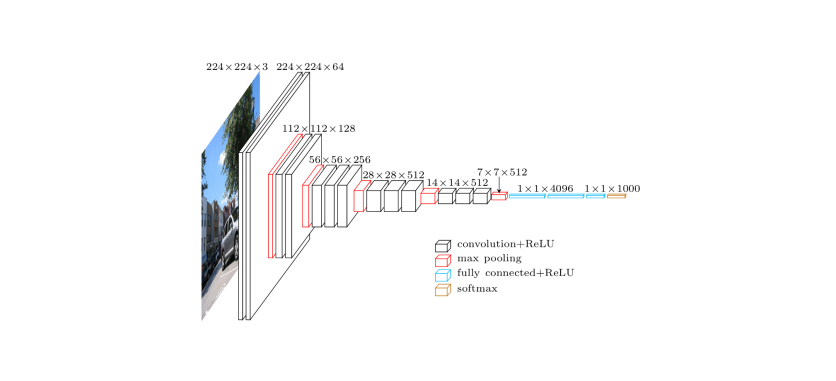
Training the model Now, we have to train the model with our dataset. First, from keras we import the pre-trained model of VGG16 with weights trained on imagenet. While loading, we include the argument include_top:False this will remove the 3 top fully connected layers. Be sure to update Keras to 2.0. Since the data set is small, we have to augment the images. Augmentation means that we have to apply different types of transformation. We are scaling the data between 1 to 255, with a image rotation range of 40 degrees along with a few other transformations.
def save_bottleneck_features(): model:applications.VGG16(weights:'imagenet', include_top:False)
datagen:ImageDataGenerator( rescale=1./255, rotation_range:40, width_shift_range:0.2, height_shift_range:0.2, shear_range:0.2, zoom_range:0.2, fill_mode:'nearest' )
generator:datagen.flow_from_directory( './data/train', target_size:(img_width, img_height), batch_size:batch_size, class_mode:None, shuffle:False )
bottleneck_features_train:model.predict_generator(generator, len(train_x)//batch_size) np.save(open('bottleneck_features_train.npy','wb'), bottleneck_features_train)
generator:datagen.flow_from_directory( './data/validation', target_size:(img_width, img_height), batch_size:batch_size, class_mode:None, shuffle:False ) bottleneck_features_val:model.predict_generator(generator, len(val_x)//batch_size) np.save(open('bottleneck_features_val.npy','wb'), bottleneck_features_vKeras has all this inbuilt so, we don’t need to worry about doing it manually using tools like opencv or scikit-image. ImageDataGenerator() has other arguments as well, you can use them if you need further augmentations. Then we proceed to create a generator with a resized image of 150 X 150 and saving the features as numpy arrays.
Before proceeding to train the model, we need to one hot encode the labels for the model to process. One hot encoding is a process to transform categorical features into a format that is more suitable for classification and regression problems. In this process we initialize an array with the shape (length of labels, number of classes). For the class that the label corresponds to labelled 1 and the remaining are 0.
def one_hot_encode(labels, length):classes_dict:{'roses':0, 'dandelion':1, 'sunflowers':2, 'tulips':3, 'daisy':4 }labels_one_hot:np.zeros(len(labels), length)for index, value in enumerate(labels):labels_one_hot[index][classes_dict.get(value)]:1return labels_one_hotAdding our classification layers is very straightforward. We just stack them like a normal keras model. Then in the model.fit() method we provide the bottleneck features of both training and validation. Now that we have 5 classes, we will add our last layer as a classification layer.
def train_top_model(): train_data:np.load(open('bottleneck_features_train.npy','rb')) val_data:np.load(open('bottleneck_features_val.npy','rb'))
model:Sequential() model.add(Flatten(input_shape:train_data.shape[1:])) model.add(Dense(256, activation='relu')) model.add(Dropout(0.5)) model.add(Dense(5, activation='sigmoid'))
model.compile(optimizer='sgd', loss='binary_crossentropy', metrics=['accuracy']) model.fit(train_data, train_y, epochs=epochs, batch_size=batch_size, validation_data=(val_data, val_y)) model.save_weights(top_model_weights_path)After this, the trained model weights are saved to disk for further usage. Here you can make the predictions as required. You could also continue to finetune the convnet to increase the accuracy of your predictions.
2936/2936 [==============================] - 3s - loss: 0.7656 - acc: 0.7800 - val_loss: 0.4998 - val_acc: 0.8000 Epoch 2/50 2936/2936 [==============================] - 2s - loss: 0.5006 - acc: 0.7999 - val_loss: 0.4990 - val_acc: 0.8000 Epoch 3/50 2936/2936 [==============================] - 2s - loss: 0.5008 - acc: 0.7995 - val_loss: 0.4985 - val_acc: 0.8000 Epoch 4/50 2936/2936 [==============================] - 2s - loss: 0.4985 - acc: 0.8000 - val_loss: 0.4982 - val_acc: 0.8000 Epoch 5/50 2936/2936 [==============================] - 2s - loss: 0.4987 - acc: 0.7999 - val_loss: 0.4981 - val_acc: 0.8000Here is how we fared on training the model after 5 epochs. It can definitely do better. Let us know in the comment section if you have better ideas to improve the model.
If the dataset is larger and similar to the original dataset, you can train the last convolutional block as well. This will help in updating the weights of the network in accordance to the use case at hand. But a word of caution, make sure that the learning rate is very low to ensure that the learned weights of the network don’t undergo drastic changes. Also the optimizer for the network should preferably be Stochastic Gradient Descent (sgd) with a very low learning rate. Other optimization methods are not used because they would cause aggressive weight changes.
There are a lot of exciting use cases for using transfer learning. It can reduce your effort considerably while building a classification model, also you could integrate other mechanisms to perform more complex tasks like object detection.
So, that’s it from our side on transfer learning, now it’s upto you guys to try it and tell us how it goes!
Subscribe to our newsletter
Get the latest updates from our team delivered directly to your inbox.
Related Posts
5 Tips to use DialogFlow the right way
This article covers 5 simple yet essential tips to save your time from making the beginner's mistakes in Dialogflow
Here's a very crucial thing people who build AI know, but you don't
The $39 billion market is something huge. But companies are mising to see a huge component when they are calculating the budget to implement a AI solution.
Apache Spark - Which language to pick?
Every language has it's own pros and cons. Zeroing down on one single language to use with Spark depends on your own project needs. Pretty straightforward, right?